
Earlier this year, we hinted that our Product Manager, Malavica Sridhar, was presenting at the annual Grace Hopper conference this fall in Houston, TX. The following is adapted from her presentation.
Introduction: Why Interpretability Matters
At CircleUp, our goal is to systematize early-stage private-market investing. In other words, we’d like to use data to efficiently, effectively, and repeatedly deploy capital at scale. And the most compelling way we believe we can achieve this vision? By having our product team — our engineers and data scientists — sit right next to our business teams. Listen to them, learn from them, and build a product that can test, validate, and productize their investing heuristics at scale.
Now, you can imagine what happens when we have two, very distinct domain experts speak to each other in two, incredibly different languages. Conversations with the data scientists on my team sound something like this.
I had a good zinger once when I proposed to decrease the overall mass of the bell curve so that our p-value would be significant, but that’s the last time I drew a bell curve in jest. Don’t mess with the Gaussian — she is sacred.
Conversations with our investing team are quite different.
Sam’s Pie Shop focus on the natural channel has resulted in distribution in over 2,000 Walmart doors. Sam’s Pie Shop is raising a $1M convertible note for continued retail rollouts.
My job as a Product Manager in this environment often boils down to being the translator of these two languages.

As I capture the requirements of what heuristic we’d like to test, and our data scientists construct a prototype for our investors, the latter consistently ask the same question: why.
Why should I believe the assertion that Sam’s Pie Shop will grow by 4x?
How certain is a data scientist that her prediction is better than my traditional, discretionary approach rooted in years of experience?
Not only do these questions demand an explanation internally (from our discretionary investment team) but often our outputs require explanation externally (from the pie shops themselves who’d like to understand why they’ve been approached for capital and how they can continue to grow).
But let me take a step back, because not all of our models require this essential explanation of “why.” In fact, we build ML models well before the final investment decision. Some of them classify outputs that are known and expected by our business teams: for example, the entity resolution system we’ve built that can systematically identify that a single product is being referenced across a set of data sources.
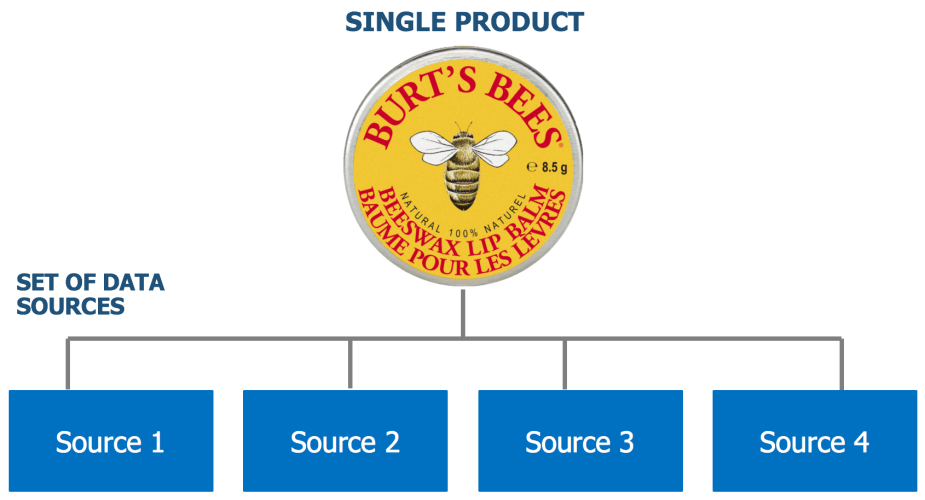
Entity resolution is the process of distinguishing between unique brands or “entities” and accurately assigning data from dispersed sources to each brand.
In these two examples alone, the degree of understanding “why” (or the degree of interpretability) varies based on the problem we’re solving. But as we’ve come to learn, every model we build benefits from some degree of interpretability. If not for the end user’s interaction and need for explanation, interpretability allows our data scientists to validate model robustness and extensibility.
Our team acknowledges these end to end advantages — how it impacts the way we test for biases in our raw data, identify flaws in feature engineering, realize inappropriate modeling techniques, and strategize an approach for model optimization.
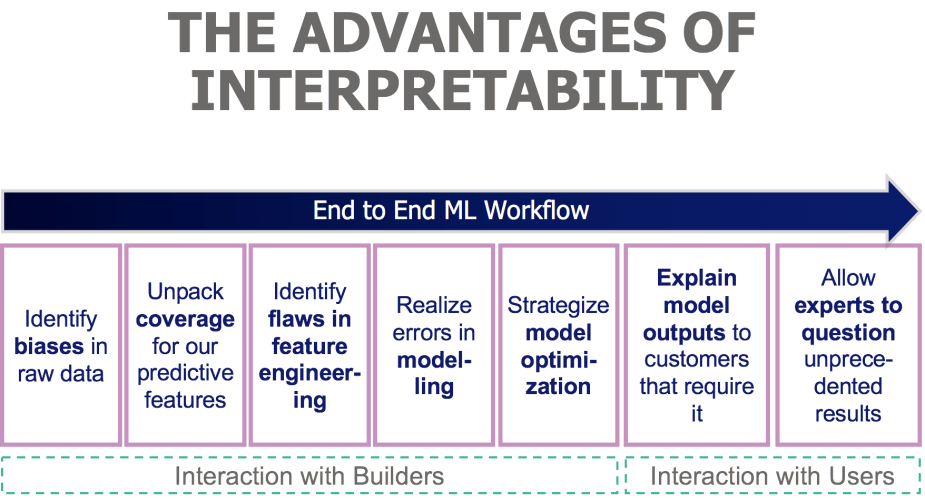 Interpretability throughout a data science workflow provides varying benefits.
Interpretability throughout a data science workflow provides varying benefits.
But how do we decide which advantages we require for our builders and customers versus don’t? What does that tradeoff look like across varying problem statements and stakeholder needs?
I’d like to share the framework we use to determine the degree of interpretability based on these end-to-end advantages. What success will look like at the conclusion of this post is if we’ve understood the three, primary drivers of what dictates level of interpretability:
- (1) The types of problems to be solved
- (2) The needs of our customers and builders
- (3) The merits of a strong feedback loop
PART I: The Problem Statement
Let’s jump into the most important component of what impacts the required level of interpretability in a model — the problem we’re solving. I like to think of the problem statement with three separate considerations:
- (A) The Context
- (B) The System, and
- (C) The Certainty.
A. The Context
What do I mean by context? I mean: how much does the problem you’re solving require explanation? What industry and function are you in? How are your customers interacting with your output? Do they use your output in isolation without seeing its performance metrics? Or do they use your output in combination with human intuition to make the final call as we often see in healthcare?
Let’s review a few examples to contextualize this a bit. In investing, let’s start with the basics — private or public market. We can deploy capital much faster in the public market — think stock market. You can jump online, buy a stock, and withdraw your commitment to this stock just as quickly. Quant investing is an application of data science on the public market. Now, although it is advantageous in model construction, end customers don’t require explanation here. In fact, investing strategies leverage computers to make elaborate decisions based on information received electronically, before humans are even capable of processing the information they observe.
On the other hand, what about a scenario where ML is used to supplement decision making ultimately made by a human? Let’s look to healthcare — where ML aids in prediction but not necessarily prescription. In a recent publication on the likelihood of bloodstream infections, ML’s aid was in the reduction of data variability and complexity and in the surfacing of information. By surfacing the likelihood of a patient having an infection, clinicians have an information advantage. But clinicians will not use this likelihood output to take action in complete isolation. And why is that?
Well, that answer gets us to the second consideration.
B. The System
In this healthcare example, our system is human. As our system complexity increases, we ought to shy away from exclusively using ML outputs in decision making. In fact, I’d go as far as to say it is irresponsible to do so. As we are both scoped and biased in the data we use, machine learning outputs fail to capture “the complete picture.” What are other attributes of the patient not captured in model training? What symptoms might have been excluded from the feature set and affect diagnosis?
“The System” additionally considers the consequence in being wrong. We’ve heard this danger before, but the risk of incorrectly using ML in decision making drives the degree of interpretability. This is somewhat obvious with humans, but it applies in investing, as well. Our discretionary equity team leverages human intuition to not only tease out the full picture — the business model viability and the sustainability of growth — but the consequence of being wrong is very real. We’re limited by the number of companies we can invest in. The limitation on our portfolio size increases our risk when compared to a systematic strategy, where we have the flexibility to invest in hundreds of companies and de-risk through diversification.
C. The Output
The final consideration in understanding the problem statement considers the output itself and how certain we are in its accuracy. At CircleUp, we think of three types of outputs:
- (i) Known Outputs
- (ii) Fuzzy Outputs, and
- (iii) Inaccessible Outputs.
(i) Known outputs are equivalent to “certainties” or classifications, where we allow black box models to take over. Although interpretability would help improve model performance, users are certain of the output and don’t require an explanation here.
(ii) The second output is the Fuzzy Output that maps together several features to compare individual observations. At CircleUp, we have a “Brand Score” that actually looks to quantify this ambiguous concept. How do we measure the brand of Pepsi or Kit Kat? This output requires some level of interpretability. Customers demand to know what the components of the “Brand Score” are and how a company can go about increasing theirs.
(iii) The final type is the Inaccessible Output, an output that tells us something about the future. Here’s where things require interpretability end to end — from model construction to the end customer interaction. Although performance metrics influence adoption here, predictions are both uncertain and inaccessible. Customers that interact with an ML output to make a final call require the context of what’s actually driving a prediction. Specifically, in the context of machine plus human, we need to know why.

If you’d like to further understand the types of outputs themselves, I encourage you to read this post from Eric Taylor.
PART II: The Customer
We’ve spent a significant amount of time dissecting the problem statement itself, and that’s an accurate representation of how important understanding this is to the degree of interpretability in an output. But as we recognize the problem statement, we ought to additionally consider the needs of our stakeholders, specifically our Customers. There are two layers to unpack when distilling the requirements of a customer and translating those needs back into product development: the needs of the customer and how the customers interact with our ML output.

I’m going to refrain from diving into each of these components individually. I’ll instead speak to how we do things differently around two of these concepts: (A) knowing the alternative and (B) improving performance.
A. Knowing the Alternative:
Now, the reason some of our modeling efforts require a higher degree of explanation is because our customers often ask how our predictions compare to what they would have chosen. Imagine answering that question, for a second. For us, adoption of a model is only achieved when we’ve validated that a prediction can beat what a discretionary investor would have chosen on her own. This seems easy. And in some cases, it is. Where we have a benchmark to define the alternative. In some cases, it isn’t. Where we don’t know what the alternative is without years of back-dated decision making data. But what we do know: interpretable outputs matter here. They drive adoption because our customers demand to understand both the why and how this prediction compares to what they would have done without a model.
B. Improving Performance:
How do we improve a model’s performance with the help of our customers? Not only do we leverage human-driven hypotheses when we seek to improve a model, we do it throughout the entirety of product development. The reason the degree of interpretability leans on the heavier side in this context is because our customers can more easily digest the effect a hypothesis has on an output.
Let’s take an example. At CircleUp, we’ve built a Distribution Model, which (like it sounds) predicts the number of retail doors a company will be in. To improve this model’s performance, we work closely with our investment team, who provide a set of hypotheses they heuristically believe to be true. These hypotheses are then leveraged by our data scientists as a path forward in model improvement.
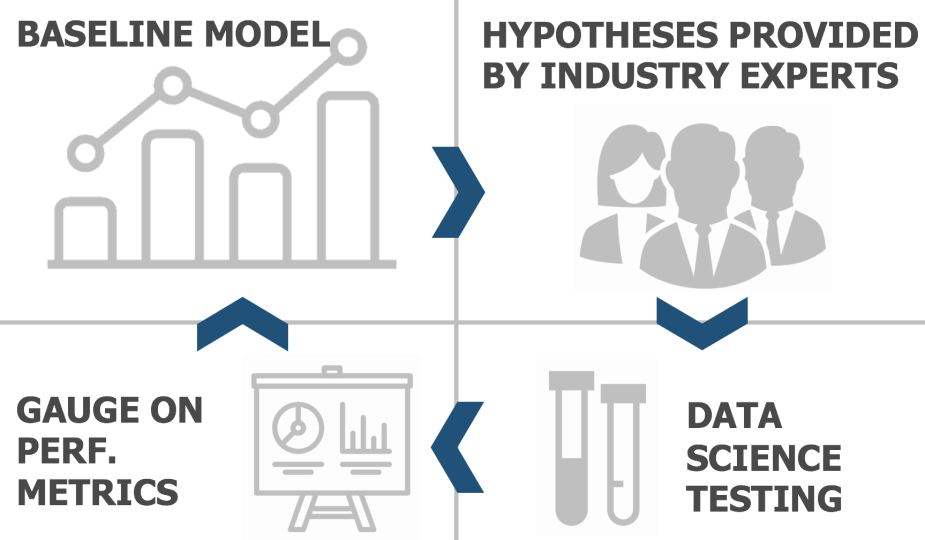
The end-to-end workflow of data science construction and iteration requires the input of our investment team, the domain experts that can help us both feature engineer and strategically identify intuitive hypotheses to test.
Here, we lean towards explanation because our customers heavily interact with nuances of the output — they are involved in its improvement. This is fundamentally different from outputs like recommendation systems. When I’m shopping on Amazon and am prompted with other products I might like, I’m neither concerned about the specifics behind the recommendation nor concerned about improvement. The ideal feedback loop in this problem is whether I chose to click and buy or not.
Part II Continued: The Builders
Now, to our Builders — the engineering and data science teams that make our ML models come to life. In the same way we require an understanding of the needs and interactions of our customers, we require the same understanding of our builders.
What are their needs? By their nature, data scientists like to understand the nitty, gritty details of both the data and insights that come from their data. End-to-end, they have a desire to internalize the origins of their data, its biases, and how it can be visualized. Data scientist needs, therefore, are far before results are even generated. They use this knowledge when sanity-checking outputs.

Perhaps the best example of this is from a data scientist on my team, who recalled for us a close mishap. Her previous firm detected rapid consumer sentiment changes via live text streams featuring Chilis and subsequently targeted an investment in the restaurant Chilis. Low and behold, last minute human due diligence revealed that people were just sharing their reactions to a Red Hot Chili Peppers concert. Biases here with data collection? Absolutely.
Additionally, when roadmapping model optimization, product teams require explanation on key drivers impacting performance. Remember the entity resolution example from earlier — the detection that the same product is referenced across several sources? Optimization here does not primarily stem from industry experts. It’s driven from the ML engineer herself who knows what data sources increase the classification’s precision and recall, both the biases and completeness of these data sources, and what orthogonal signals are fundamentally missing. It’s challenging for data scientists to construct optimization strategy without internalizing the underlying features. And here’s where black box classification systems demand explanation without a sacrifice on its performance.
Part III: The Feedback Loop
Like interpretability, the feedback loop can exist to varying degrees, as well. And depending on the problem statement and the customer’s interaction with the model’s construction and optimization, we can choose to incorporate multiple layers of feedback.

On one end where we expect close to no interaction with end customers, the feedback loop consists of actions independently scoped to the user. Zillow’s house price algorithm serves to provide the best estimate for its users. I’d imagine Zillow’s feedback loop with customers on this estimate is somewhat minimal — users with similar price range preferences click on a similar cohort of houses.
On the other end, when we think about the surgeon who uses ML to inform diagnosis, she demands to know the entirety of model construction — what data went into creating this model? What features are missing? What does the training data look like? How biased is the training data? How can I offer my expertise to improve model performance?
At CircleUp, we seek domain expertise across the board: in feature and training data collection, in model construction, in post-mortem analysis of feature importance, and in model optimization. As a Product Manager in this environment, it’s vital to set context and expose truths, biases, and limitations early. Because of how involved our customers are in the model development.
A final thought about feedback loops that we often think about. Are our feedback loops biased? It’s interesting to think about the objectivity that we strive for in data collection, processing, and modeling and the subjectivity that arise from user feedback. Is this a bias we strive to incorporate or will it affect model extensibility?
Final Thoughts: Interpretability > Accuracy
We are in the age of data consumption. The data we’re using is comin’ in hot, and we’re drinking it through a fire hose. And quite frankly, we often do not have the extensive breadth of historical data to effectively conduct the rigorous back-testing necessary for recommendations.
We live in a world where interpretability triumphs — not only because of the problems we’re trying to solve, the customers’ interaction with the output, and the data scientists’ ability to improve performance — but because we have to sanity check. We have to dissect what’s actually happening to influence an output and identify its potential flaws.
I encourage you to question “why” so we can better understand the biases in our data, the features that are driving performance metrics, and the insights that impact decisions — made with or without a human.